敏感词、文字过滤是一个评论类站点必不可少的功能,设计一个好的,高效的过滤算法是非常重要的。
DFA简介
在实现文字过滤的算法中,DFA是唯一比较好的实现算法。
DFA即Deterministic Finite Automaton,也就是确定有穷自动机,它是通过event和当前的state得到下一个state,即event+state=nextState。
下图展示了其状态的转换
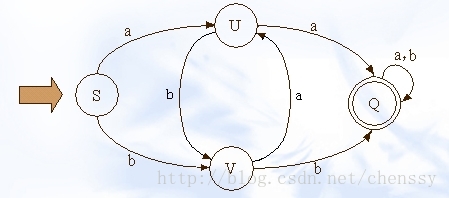
在这幅图中大写字母(S、U、V、Q)都是状态,小写字母a、b为动作。通过上图我们可以看到如下关系:
S+a=>U;S+b=>V;U+b=V
在实现敏感词过滤的算法中,我们必须要减少运算,而DFA算法中几乎没有什么计算,有的只是状态的转换。
使用 JavaScript 实现一个DFA算法
- 构建敏感词状态机并放入——hash表
在敏感词匹配之前,我们需要先创建一个DFA算法模型,后续的匹配算法基于此模型进行计算。这里我们采用Map作为其数据结构。
Map相对于传统的Object对象有如下几个优点(mozilla开发文档)
- 一个Object的键只能是
字符串或者Symbols,但一个 Map 的键可以是任意值,包括函数、对象、基本类型。- Map 中的键值是有序的,而添加到对象中的键则不是。因此,当对它进行遍历时,Map 对象是按插入的顺序返回键值。
- 你可以通过size 属性直接获取一个 Map 的键值对个数,而 Object 的键值对个数只能手动计算。
- Map 可直接进行迭代,而 Object 的迭代需要先获取它的键数组,然后再进行迭代。
- Object 都有自己的原型,原型链上的键名有可能和你自己在对象上的设置的键名产生冲突。虽然 ES5 开始可以用 map = Object.create(null) 来创建一个没有原型的对象,但是这种用法不太常见。
- Map 在涉及频繁增删键值对的场景下会有些性能优势。 结构如下:
interface ISensitiveMap:Map<key:any>{
laster:boolean, // 是否最后一个文字
[char]:ISensitiveMap // 下一state
}
举例敏感词有着这么几个 [‘日本鬼子’,’日本人’,’日本男人’],那么数据结构如下(图片引用参考文章)

从图我们可以得到如下的数据结构:
{
"laster":false,
"日":{
"laster":false,
"本":{
"laster":false,
"鬼":{
"laster":false,
"子":{
"laster":true
}
},
"人":{
"laster":true
},
"男":{
"laster":false,
"人":{
"laster":true
}
},
}
}
}
具体过程如下:
- 在Map中查询“日”看其是否在Map中存在,如果不存在,则证明已“日”开头的敏感词还不存在,则我们直接构建这样的一棵树。跳至3;
- 如果在Map中查找到了,表明存在以“日”开头的敏感词,设置Map = Map.get(“日”),跳至1,依次匹配“本”、“人”;
- 判断该字是否为该词中的最后一个字。若是表示敏感词结束,设置标志位laster = true,否则设置标志位laster = false。
具体代码实现(Typescript):
class DFA{
sensitiveMap:Map,
/**
* 构建敏感词库
*
* @param {Array<string>} sensitiveWordList
* @memberof DFA
*/
public genSensitiveWordHashMap(sensitiveWordList: Array<string>): void {
if (this.sensitiveMap) {
console.log('rebuild map');
}
// 构造根节点
this.sensitiveMap = new Map();
for (const word of sensitiveWordList) {
this._insertWord(word);
}
}
/**
* 往敏感词库添加词汇
*
* @private
* @param {*} word
* @memberof DFA
*/
private _insertWord(word) {
let nowMap: Map<string, any> = this.sensitiveMap;
// 依次获取字
for (let i = 0; i < word.length; i++) {
const char = word.charAt(i);
const wordMap: Map<string, any> = nowMap.get(char);
if (wordMap) { //如果存在该key,直接赋值
nowMap = wordMap;
} else { //不存在则构建一个map,同时将laster 设置为false,因为他不是最后一个
nowMap.set('laster', false);
let newMap = new Map<string, any>();
newMap.set('laster', true);
nowMap.set(char, newMap);
nowMap = nowMap.get(char);
}
}
}
}
- 匹配敏感词 检索过程使用 Map 的get方法,找到就证明该文本含有敏感词,否则不为敏感词。过程如下:假如我们匹配“中国人民万岁”。
- 第一个字“中”,我们在Map中可以找到。得到一个新的map = hashMap.get(“”)。
- 如果map == null,则不是敏感词。否则跳至3
- 获取map中的laster,通过laster是否等于true来判断该词是否为最后一个。如果isEnd == true表示该词为敏感词,否则跳至1,依次匹配“国”、“人”。。。
通过这个步骤我们可以判断“中国人民”为敏感词,但是如果我们输入“中国女人”则不是敏感词了。
class DFA{
...
/**
* 配置词库
*
* @param {*} word 要匹配的文本
* @returns
* @memberof DFA
*/
public matchSensitive(word): { match: boolean, word?: string, everMatch?: boolean } {
let result = false;
if (!this.sensitiveMap) {
return { match: result };
}
// 过滤单词
let nowMap = this.sensitiveMap;
let matchWord = '';
let everMatch = false;
for (let i = 0; i < word.length; i++) {
const char = word.charAt(i);
const wordMap: Map<string, any> = nowMap.get(char);
if (wordMap) {
everMatch = true;
if (wordMap.get('laster') === true) {
matchWord += char;
result = true;
break;
}
nowMap = wordMap;
matchWord += char;
} else {
result = false;
}
}
return {
match: result,
word: result ? matchWord : '',
everMatch: !result ? everMatch : false
};
}
}
调用
function matchSensitive(map: DFA, word: string) {
let match = false;
const result = map.matchSensitive(word);
// 如果敏感词匹配过一半,说明接下来的文本有再次被匹配的可能
if (result.match === false && result.everMatch === true) {
return matchSensitive(map, word.slice(1, word.length));
} else if (result.match === true) {
match = true;
}
return match;
}
const map = new DFA();
const sensitiveWordList = ['日本鬼子', '日本人', '日本男人'];
map.genSensitiveWordHashMap(sensitiveWordList);
const word = '日本鬼子是谁?';
const result = matchSensitive(map, word);
